





国产GPU加速开源生态融合:摩尔线程Day-0支持混元翻译新版本
在AI大模型技术快速迭代的浪潮中,国产GPU的生态适配能力正成为业界关注的新焦点。近日,腾讯混元宣布推出并开源其翻译模型1.5版本。在该模型发布同日,摩尔线程即宣布,已率先完成该系列模型在其智能SoC芯片“长江”上的深度适配与高效部署。这一快速的技术响应,为国产GPU的软件生态建设与AI应用落地提供了新的实践案例。
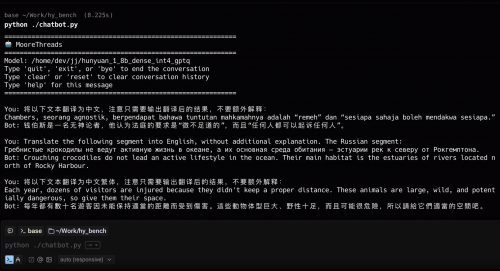
腾讯此次开源的混元翻译模型1.5包含两个版本:参数量为1.8B的Tencent-HY-MT1.5-1.8B和7B的Tencent-HY-MT1.5-7B。两个模型均重点支持33个语种互译以及5种民汉语言或方言,覆盖了从中文、英语等常见语种到捷克语、冰岛语等小语种。其中,1.8B模型主要面向手机等消费级硬件,经过量化后可支持端侧直接部署和实时翻译;7B模型则是此前在WMT25比赛中获得30个语种翻译冠军模型的升级版,重点提升了翻译准确率,减少了译文中的注释和语种混杂现象。
快速响应的技术实践
摩尔线程此次适配工作的核心,在于其MUSA架构与大模型生态构建的兼容性。其高易用性的底层设计,旨在降低开发者在模型适配与迁移过程中的研发成本,从而提升项目开发效率。此次从模型发布到完成适配的时间极为短暂,这种快速响应能力,在一定程度上体现了国产GPU在底层技术栈上的成熟度。
事实上,这并非摩尔线程首次展现其快速的生态适配能力。根据其官方信息,在DeepSeek、通义千问QwQ-32B/Qwen3、混元-A13B等热门模型发布的首日,其均已完成适配并实现稳定支持。这种持续性的“Day-0”支持能力,正逐渐成为相关企业在构建AI算力生态时的一个技术特点。
开源生态与行业应用
腾讯混元翻译模型目前已在腾讯内部多个业务场景中落地应用,包括腾讯会议、企业微信、QQ浏览器、翻译君等产品。此次将模型开源,并在Github和Huggingface等社区上线,旨在进一步方便广大开发者使用,促进技术创新与应用探索。
对于摩尔线程而言,积极参与和支持此类开源生态,是其助力开发者充分挖掘硬件潜能的途径之一。通过与大模型团队的紧密协作与快速适配,国产GPU能够更早地进入开发者的技术选型视野,开拓更多的AI应用场景,这对于整个软硬件生态的良性发展具有积极意义。
构建持续发展的算力基础
当前,人工智能的竞争不仅是模型的竞争,也是算力基础与工程化能力的竞争。将先进的AI模型高效、稳定地部署在硬件上,是实现其价值的最终环节。摩尔线程此次对混元翻译模型1.5的快速支持,可以看作是国产GPU在这一关键环节上进行的一次具体实践。其目标是通过坚实可靠的底层技术,为人工智能创新成果的工程化转化与规模化落地提供支撑。
随着大模型技术持续演进,其对底层算力的需求与生态兼容性提出了更高要求。此次摩尔线程的快速适配,为观察国产GPU如何响应瞬息万变的技术生态提供了一个窗口。未来,持续构建更开放、敏捷且稳健的软硬件协同生态,将是相关企业服务开发者、推动AI应用广泛落地的关键。
免责声明:本内容为广告,相关素材由广告主提供,广告主对本广告内容的真实性负责。本网发布目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责,广告内容仅供读者参考,如有疑问请联系:0564-3996046。